The Joy of Joyplots
Recently I've been pretty intrigued by Joyplots. Joyplots are overlapping line plots that sort of look like mountain ranges. They are great for visualizing changes in distribution over time or by some other factor. The name Joyplot is in reference to the cover art for Joy Division's album - Unknown Pleasures (https://cran.r-project.org/web/packages/ggjoy/vignettes/introduction.html).
At work, a lot of questions revolve around "how has x changed over time" or "how is x different segmented by y". I'm always struggling to give a concise and truthful answer while also showing context. By providing one number (x has changed by this % relative to the same period last year), you are removing context in order to drive a decision through simplicity. With visualization it is possible to both show a summarized concise answer, while also providing context. Joyplots are another tool to illustrate context through visualization.
So let's get started with Joyplots, I decided to experiment with a dataset about Netflix shows and ratings from data.world (https://data.world/chasewillden/netflix-shows). This dataset contains ratings for 496 distinct shows and movies. The dataset is pretty good, but by no means is reflective of everything on Netflix. Mostly it was just a fun excuse to do some visualization.
After bringing in the dataset and cleaning it up a bit, it's time to make some joyplots -
The first joyplot will look at Netflix Ratings by movie release year. You can see how the distribution of ratings have shifted based on the release date of the content.
User ratings appear like they are increasing over time, even as the rating distributions get wider

People rated content released in 2016 and 2017 very highly, especially when you consider the growth in Netflix content released in 2016 and 2017
When we look at the same data in a box plot, we see that there were many years where the mean was actually at the same level or higher as 2016 or 2017. This is why it's great to have a combination of something that shows distribution in addition to raw values. When we look at the count of titles by year released, nearly 200 out of the 500 pieces of content reviewed in this data set were released in the last two years.


Here are the mean scores by year. Looking at this gives us even more insight. The release years of 2001, 2005, 2011 and 2017 all had the highest mean values by year.

Ok so now we understand the trends by year, but what about the trends by content rating? In our second joyplot you can see that there are some interesting patterns with content ratings and user scores. I really like the content ratings where it looks like there are two humps or peaks, specifically with TV-G, PG- 13 and rated R movies.
People Are very passionate about children's programming, and they love their TV with or without adult themes

When you look a the box plot, it seems that TV content has a higher mean rating than movie content. Like in the joy plot, it seems that TV-G and G have the widest distribution, people are really passionate about their children's programming.

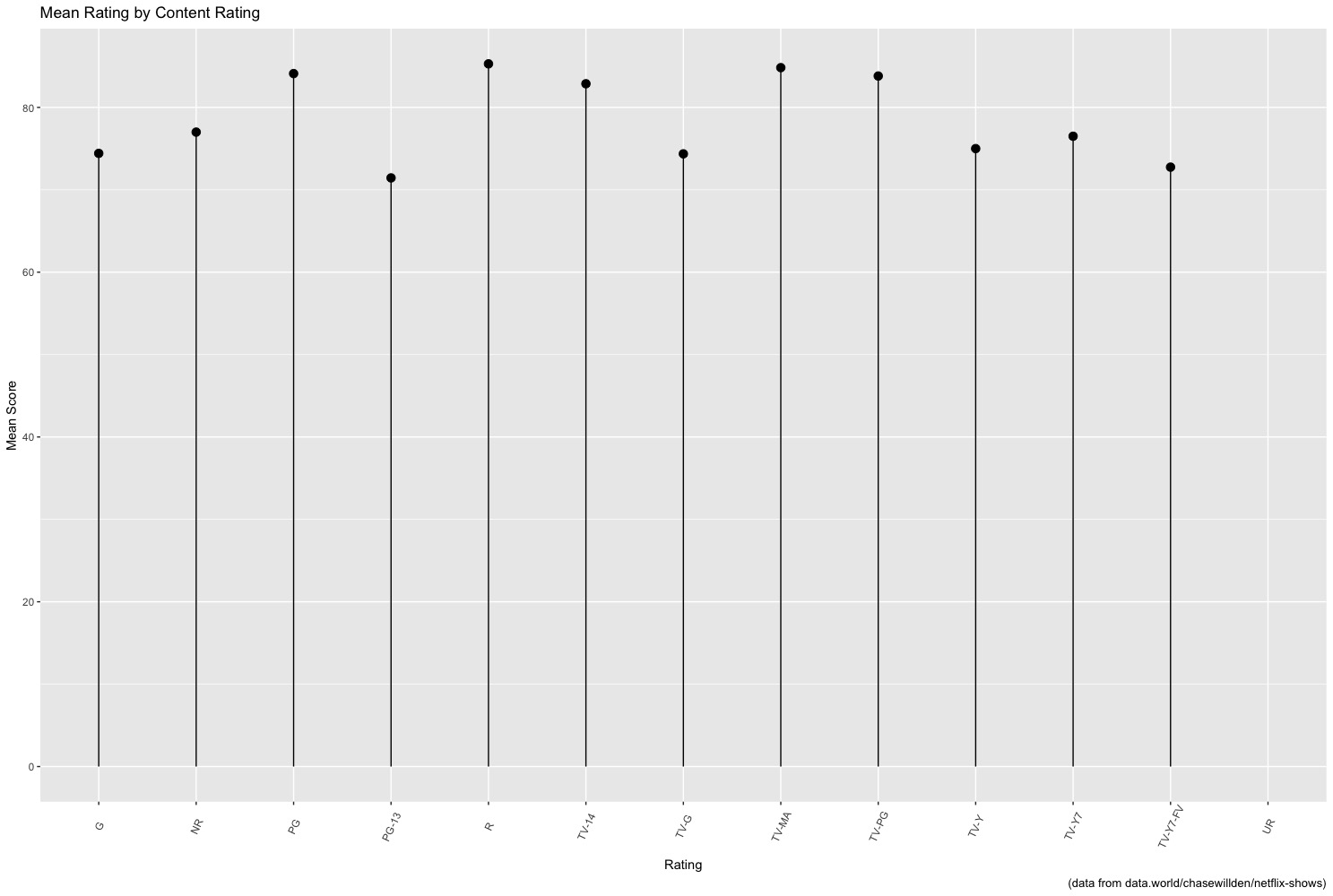
Here are the mean scores by content rating. When you look at the mean values rather than the box plots, movies and TV are more equally distributed by rating.
people really love 13 reasons why, and kind of hate Saved by the Bell and Portlandia
What individual shows are driving this ratings distribution by Year and content rating? Let's look at the top shows, by rating in the data set. 13 reasons why is the top rated show in the dataset. Whatever your feelings are about that movie and the context around it - its viewers are passionate. Bones is also ranked within one point of Breaking Bad, illustrating that the people love a formulaic traditional TV procedural with a strong will they or won't they storyline. Humans are complex creatures we can like both Breaking Bad and Bones ok.


Let's look at the bottom shows - personally I'm a little shocked that Curious George and 90210 have such low user ratings. The fact that Portlandia is rated a 62 is pretty hilarious to me - hipster backlash alert.


Joyplots, boxplots, and summary metrics all provide information but in slightly different ways. With this example, hopefully the value of a joyplot, boxplot and summary plots are a little clearer.
See code below to recreate yourself!
List all tables in the dataset:
```{r list tables}
library(data.world)
# Datasets are referenced by their URL or path
dataset_key <- "https://data.world/chasewillden/netflix-shows"
# List tables available for SQL queries
tables_qry <- data.world::qry_sql("SELECT * FROM Tables")
tables_df <- data.world::query(tables_qry, dataset = dataset_key)
# See what is in it
tables_df$tableName
```
Try a sample query, if any tables exist:
```{r sample query}
if (length(tables_df$tableName) > 0) {
sample_qry <- data.world::qry_sql(sprintf("SELECT * FROM `%s`", tables_df$tableName[[1]]))
sample_df <- data.world::query(sample_qry, dataset = dataset_key)
sample_df
}
qry <- data.world::qry_sql(sprintf("SELECT * FROM `%s`", tables_df$tableName[[6]]))
netflix.df <- data.world::query(qry, dataset = dataset_key)
#CleanData
str(netflix.df)
myvars <- c("title", "rating", "user_rating_score","user_rating_size","release_year")
netflixdf2 <- netflix.df[myvars]
netflixdf2 <- distinct(netflixdf2, title, rating, user_rating_score,user_rating_size,release_year)
str(netflixdf2)
netflixdf2$release_year<-as.factor(netflixdf2$release_year)
netflixdf2$title<-as.factor(netflixdf2$title)
netflixdf2$rating <- as.factor(netflixdf2$rating)
is.numeric(netflixdf2$user_rating_score)
is.numeric(netflixdf2$user_rating_size)
str(netflixdf2)
#Joyplots
joyplot1 <- ggplot(netflixdf2, aes(x = netflixdf2$user_rating_score, y = netflixdf2$release_year, fill = netflixdf2$release_year,title(legend.title="Release Year"))) +
geom_joy(scale = 3.75) +
theme_joy(grid = FALSE)
joyplot2 <- ggplot(netflixdf2, aes(x = netflixdf2$user_rating_score, y = netflixdf2$rating, fill = netflixdf2$rating,title(legend.title="Rating"))) +
geom_joy(scale = 3) +
theme_joy(grid = FALSE)
joyplot1 + labs (title = "Netflix User Ratings by Release Year",x = "User Rating",y = "Release Year", fill = "Release Year",caption = "(data from data.world/chasewillden/netflix-shows)")
joyplot2 + labs (title = "Netflix User Ratings by Content Rating","Netflix User Ratings by Release Year",x = "User Rating",y = "Content Rating",fill = "Content Rating",caption = "(data from data.world/chasewillden/netflix-shows)")
#BoxPlots
qplot(release_year, user_rating_score, data=netflixdf2, geom=c("boxplot"),
fill=release_year, main="User Rating by Year",
xlab="Year", ylab="Rating")
qplot(rating, user_rating_score, data=netflixdf2, geom=c("boxplot"),
fill=rating, main="User Score by Content Rating",
xlab="Content rating", ylab="User rating")
#Create Data Frame for Titles by Year
TitlesByYear <- netflixdf2 %>% count(release_year, sort = TRUE)
#Create Plot for Count of Titles by Year
TitilesbyYearPlot <- ggplot(data=TitlesByYear, aes(release_year, y=n, group=1)) +
geom_area(color = "blue")+
geom_point(color = "grey")
TitilesbyYearPlot + labs (title = "Count of Movies / TV Shows Scraped by Release Year",x = "Release Year",y = "Titles", fill = "Release Year",caption = "(data from data.world/chasewillden/netflix-shows)")
#Subset top / bottom titles
Top <- netflixdf2[netflixdf2$user_rating_score >= 96 & netflixdf2$user_rating_score < 100 ,]
Bottom <- netflixdf2[netflixdf2$user_rating_score <= 62 ,]
# Plot top / bottom titles
qplot(user_rating_score,title, data=Top, geom=c("auto"), color = release_year ,
main="Top Ratings",
xlab="Rating", ylab="Title")
qplot(user_rating_score,title, data=Top, geom=c("auto"), color = rating ,
main="Top Ratings",
xlab="Rating", ylab="Title")
qplot(user_rating_score,title, data=Bottom, geom=c("auto"), color = release_year ,
main="Bottom Ratings",
xlab="Rating", ylab="Title")
qplot(user_rating_score,title, data=Bottom, geom=c("auto"), color = rating ,
main="Bottom Ratings",
xlab="User Rating", ylab="Title")
# Create summary stats
library(psych)
des.mat<- describeBy(netflixdf2$user_rating_score,netflixdf2$release_year,mat=TRUE)
des.rating <- describeBy(netflixdf2$user_rating_score,netflixdf2$rating,mat=TRUE)
ScoreByYearPlot <- ggplot(des.mat, aes(x=group1, y=mean)) +
geom_point(size=3) +
geom_segment(aes(x=group1,
xend=group1,
y=0,
yend=mean)) +
labs(title="Mean Score by Year",
xlab="Mean Score", ylab="Year",
caption="(data from data.world/chasewillden/netflix-shows)") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
ScoreByRatingsPlot <- ggplot(des.rating, aes(x=group1, y=mean)) +
geom_point(size=3) +
geom_segment(aes(x=group1,
xend=group1,
y=0,
yend=mean)) +
labs(title="Mean Score by Year",
xlab="Mean Score", ylab="Year",
caption="(data from data.world/chasewillden/netflix-shows)") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
# Create lolipop plots of summary means
ScoreByRatingsPlot + labs (title = "Mean Rating by Content Rating",x = "Rating",y = "Mean Score", caption = "(data from data.world/chasewillden/netflix-shows)")
ScoreByYearPlot + labs (title = "Mean User Rating by Content Rating ",x = "Year",y = "Mean Score",caption = "(data from data.world/chasewillden/netflix-shows)")
```
## Next Steps
* View our quickstart guide:
```
vignette("quickstart", package="data.world")
```
* Learn more at https://github.com/datadotworld/data.world-r