How Does the NFL Use Facebook? An Excuse to Connect to the Facebook API Using R
A couple of weeks ago, I stumbled on a neat blog - "Think to Start". On think to Start he has a number of tutorials with R. The tutorials have clear business applications, so I decided to try a few out.
When playing around with the Facebook Open Graph API, I realized that you could pull out data for posts from any public Facebook page. With each post, you also get dimensions like time posted, day of the week and the number of likes, comments, and shares.
With this API I was able to capture this data for 1,338 updates from the official NFL Facebook page (Facebook.com/NFL), from 10/24/12 to 12/04/14.
With a little data clean up, we can do some very cursory, yet pretty interesting analysis with both R and excel.
The first thing I wanted to do, after cleaning up the data, was to visualize it to see if there was anything unexpected or surprising.
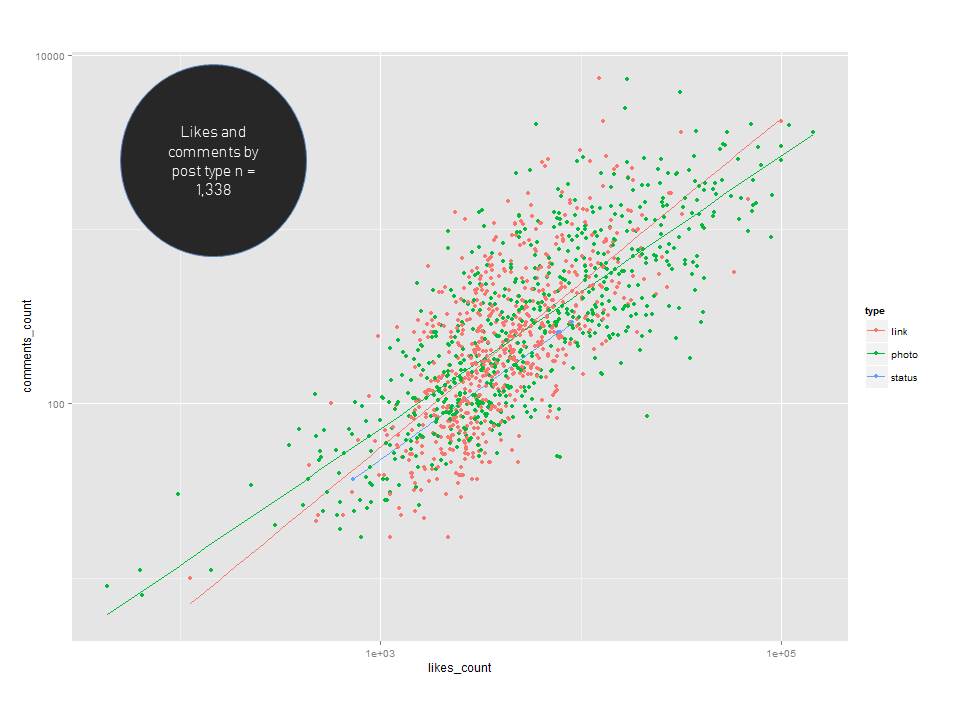


Once we brought in those initial visualizations, I wanted to dig a little deeper. I added some median lines and added a histogram for the number of likes, comments and shares by post type.
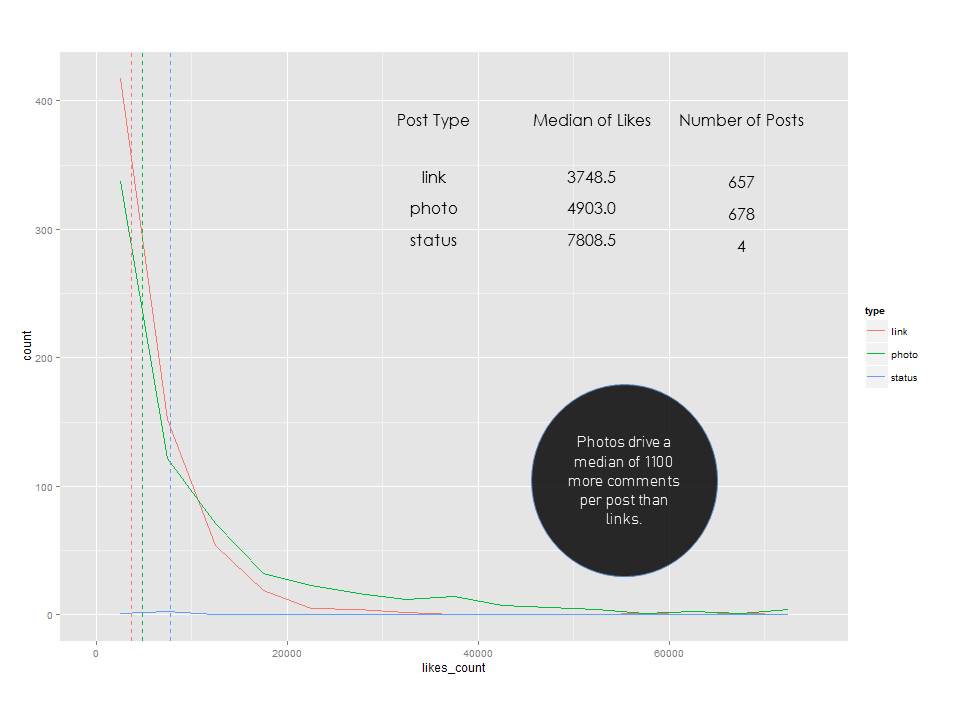

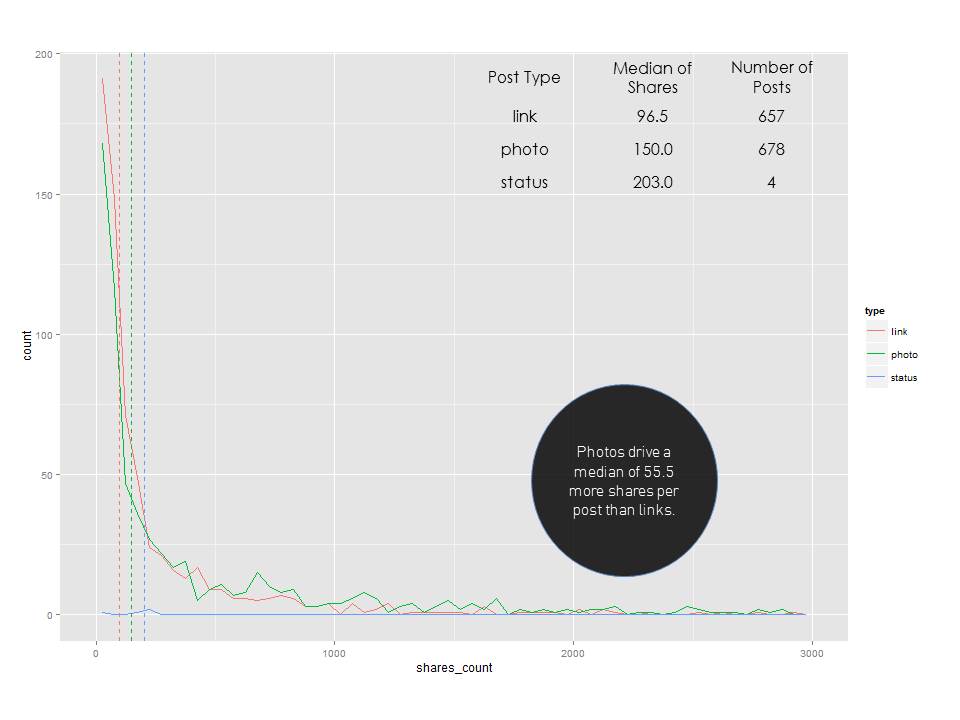
After seeing these histograms, I really wanted to understand the distribution a little better by overlapping post types.

I think it's pretty clear now that photos outperformed the "status" update type in terms of driving fan engagement for the NFL. If we know that post type has some sort of an impact on the amount of engagement, what about the day of the week?

Hmmm - It seems that engagement follows a pretty specific pattern...

Now that we've figured out that the NFL can literally not post ENOUGH, it got me thinking about the content of the updates themselves. Was there any way to do some text mining to figure out the frequency of certain words and how they drive specific types of engagements? Using R again, I was able to create a word cloud which omits common words where the words are sized based on frequency. There isn't that much to be learned here yet - The NFL talks a lot about specific players, teams, fantasy football and itself.

What happens when we compare the frequency of words in the 100 posts that are most liked versus 100 least liked? This is starting to get more interesting. People sure do love to wish their favorite player happy birthday with a "like."

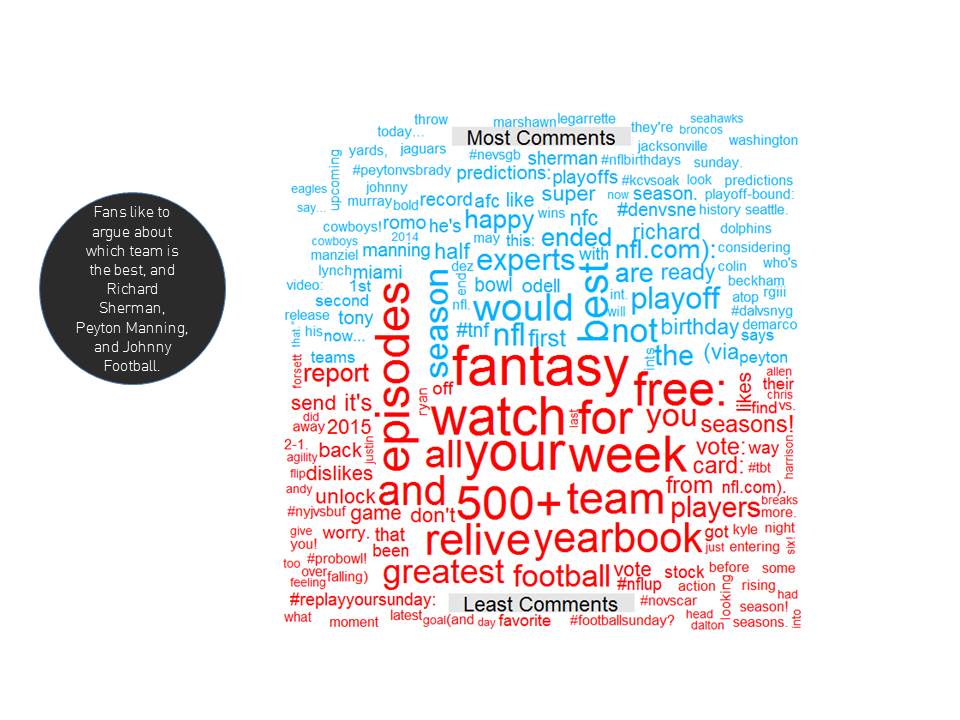
What about the 100 most commented on posts versus the least commented on posts? You can see that there are a couple of players here that drive a lot of "discussion." Specifically Richard Sherman, Peyton Manning, and Johnny Manziel. Again - no one is interested in re-watching games or engaging with NFL promotions.
What about word frequency in content that is the most or least shared? That amazing Odell Beckham catch dominates, as well as specific marquee games.

Pretty interesting, to summarize:
1) The NFL posts a lot on Facebook , evenly distributed between links and photos.
2) Photos drive more engagement than links.
3) The favorite day for the NFL to post is on Monday, and that is also the day where the is the highest amount of fan engagement per post.
4) The amount of engagement per post fits with the average number of posts per day (R squared of .42), suggesting that the NFL could be posting even more.
5) If you want to start a flame war with NFL fans - bring up Peyton Manning, Johnny Manziel or Richard Sherman. I can't guarantee that the comments will be worth reading however :)
I've included the code below for bringing the posts in, the visualizations and the wordcloud comparison.
Use RFacebook to bring in posts
Create Frequency Word Cloud
Create Comparison Word Cloud From Two CSVs